
Deleting a large amount of data from a SQL Server table can be a resource-intensive task. Whether it’s for routine maintenance or data cleanup, managing the deletion process efficiently becomes crucial for maintaining database performance.
In this blog post, we’ll explore the strategy of deleting data in batches using SQL Server, providing a balance between performance and resource utilization.
Deleting Data in Loops SQL Server
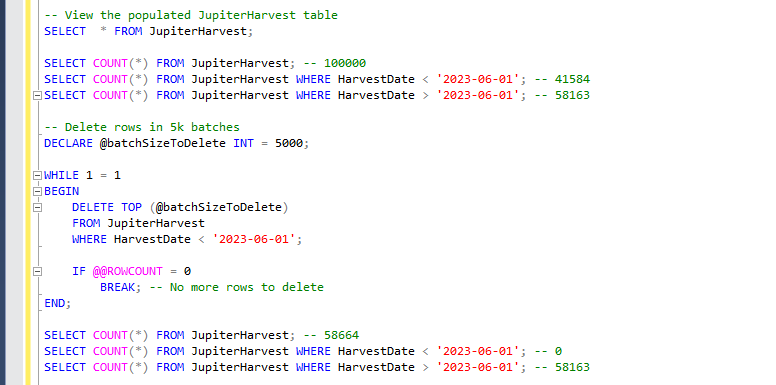
Deleting data in large tables is often a performance-intensive operation. Deleting records in batches helps mitigate the impact on system resources and allows for more manageable transaction sizes. Below is an SQL script demonstrating how to delete data from the JupiterHarvest demo table in batches.
-- Delete data in loops
DECLARE @batchSizeToDelete INT = 5000;
WHILE 1 = 1
BEGIN
DELETE TOP (@batchSizeToDelete)
FROM JupiterHarvest
WHERE HarvestDate < '2023-01-01';
IF @@ROWCOUNT = 0
BREAK; -- No more rows to delete
END;
Considerations for Deleting in Batches
While deleting in batches offers improved performance, it’s essential to consider a few factors:
- Transaction Log Size: Batching helps control the growth of the transaction log, but be mindful of transaction log size during the process.
- Table Locking: Large-scale deletions can result in table locks, impacting concurrent operations. Choose an appropriate batch size based on your database’s workload.
- Index Maintenance: Monitor and update indexes after the deletion process to maintain query performance.
In conclusion, deleting data in batches is a strategic approach to efficiently manage large datasets. Consider the factors mentioned above, and tailor the batch size to suit your specific database environment.